Introduction
Natural language processing is something I find fascinating and a technique that exists in that realm is called Topic Modeling. Topic modeling is an unsupervised learning approach that essentially tries to assign topics to documents.
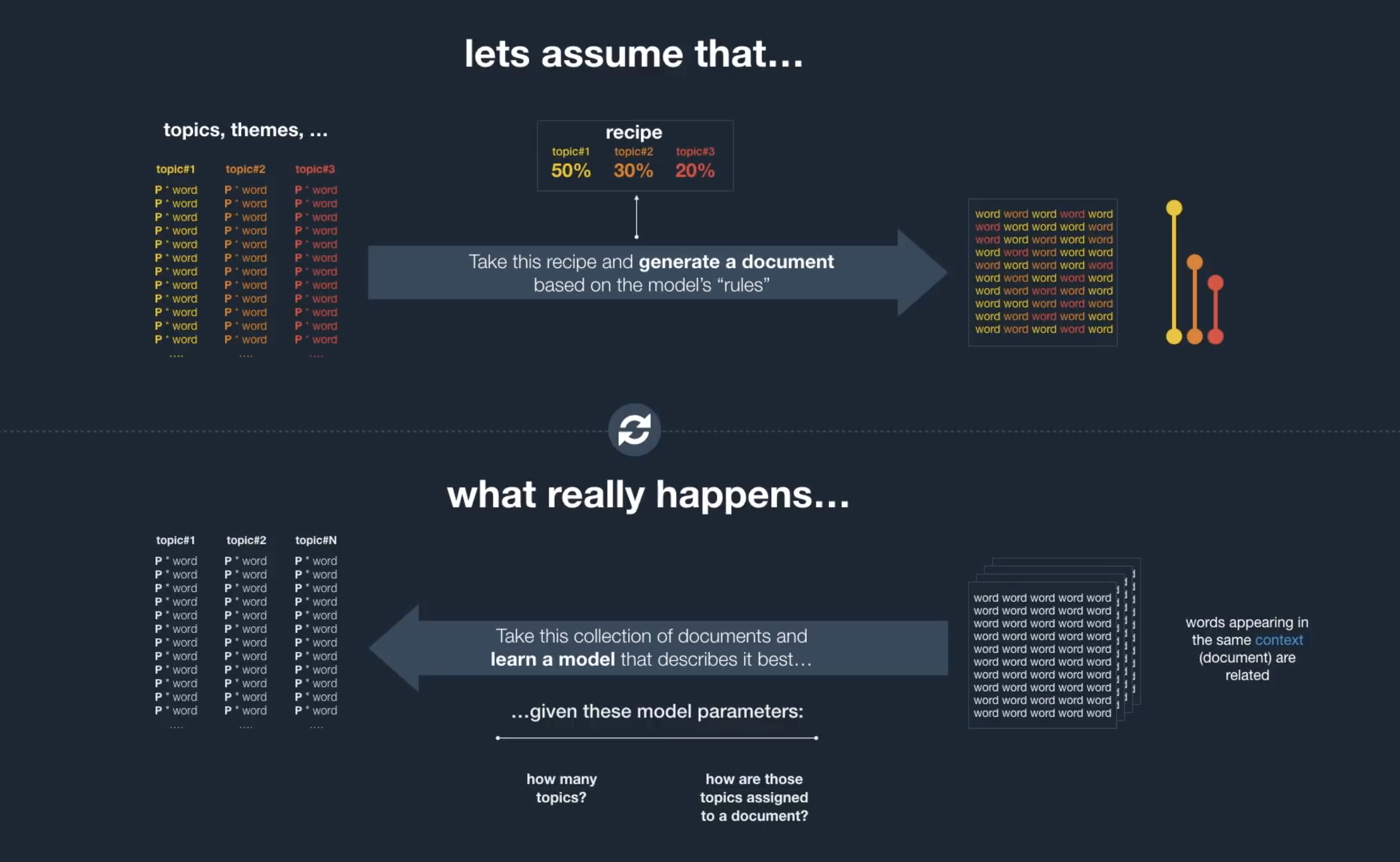
Before jumping in, let me provide a background on the terms that will be used in this post. Say we have a collection of texts in the form of movie reviews, the entire collection is called a ‘corpus’. This corpus is further made up of individual reviews or ‘documents’. Each such document has one or more sentences which is a collection of words. Now that you know what ‘corpus’ and ‘document’ stand for, let’s move on to Topic Modeling itself.
Topic Modelling
Topic modeling using Latent Dirichlet Allocation (LDA) works by assigning topics to each document. LDA uses the premise that each topic is a just a distribution of words and each document is a distribution of topics. For example, a corpus of news articles could have topics such as ‘sports’, ‘politics’, ‘business’ etc. and each of those topics could have a distribution of words. The topic ‘sports’ could have words like football, athlete, basketball in its distribution while the topic ‘politics’ could have words like prime minister, president, policy.
The reason this method is termed unsupervised is because there’s no way to know for sure how many topics really exist. For say movie reviews, if the reviews were only for Sci-fi movies, essentially a single topic is enough, but if one chooses 5 topics the algorithm would try to find words for topics such that the corpus can be split into 5 different groups. You can think of K-means but for texts. Topic Modeling essentially tries to cluster texts together. It extracts latent and abstract meanings from the texts.
Given that we already have words to process in the form of a corpus, the algorithm’s job is to:
- find topics for each word in a document so that it can learn the distribution of words for each topic
- find the distribution of topics for each document given the words in that document.
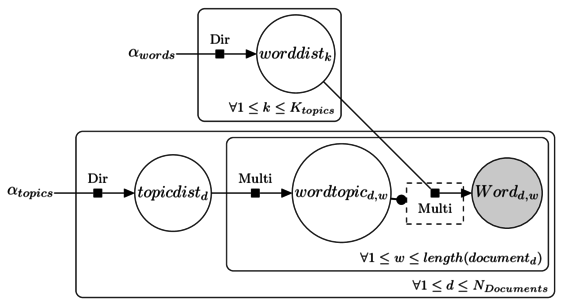
The image above shows the entire process. The node in grey is what we are given in the corpus: Wordd,w
For each of the K topics, there is a word distribution: worddistk, which uses a dirichlet prior: alphawords
Further, there is a topic for each word in a given document: wordtopicd,w
Finally, there is a topic distribution for each document: topicdistd, which uses a dirichlet prior: alphatopics
Except the words, everything else in this figure is latent or unknown. Think of it in this way, each document is created with a recipe. The recipe tells you which topics and how much of each of those needs to be included in the document. For instance, a document could be 40% sports, 35% business and 25% culture. Once the recipe is set, choose words from each of those topics in the proportion of their % and create the document. The most challenging thing here is to know how many topics actually exist.
Now that you have a background, let’s dive into the data. For more information on how it is implemented in Python with a step-by-step breakdown, you can check out this link
Data
The dataset was originally picked up from: kaggle which has ~35k movies. I filtered and cleaned the dataset and ended up with ~22k movies. Each movie has a plot synopsis that served as the text, and the entire collection of these movie plots made up the corpus. I filtered the dataset so that it only contains movies from US, Canada, Britain, India (Bollywood) and Australia. Next up is the cleaning portion of the project.
Preprocessing
As I mentioned earlier, each topic in a topic model should learn a distribution of words for each topic. In order for the words to be representative of a certain topic, we need to filter the words so that each document only contains the most relevant words from which a topic can be inferred.
For example, in the sentence: Football is the most exciting of all sports and has the biggest fan following in the world
, the relevant words are Football, exciting, sports, world, and can easily be interpreted by a human to be a sentence related to sports. For a machine to understand this, we need to strip the sentence of unnecessary words (or Stopwords) such as is, the, of, has etc.
This preprocessing can be done in a lot of different ways, I used Gensim, nltk and spacy to preprocess the corpus.
Preprocessing using NLTK & Gensim
Preprocessing using Spacy
While everyone has their own style and way of preprocessing texts, I personally like working with spacy for preprocessing. It’s extremely powerful and has a lot of functionalities for implementing advanced techniques and models.
Modeling
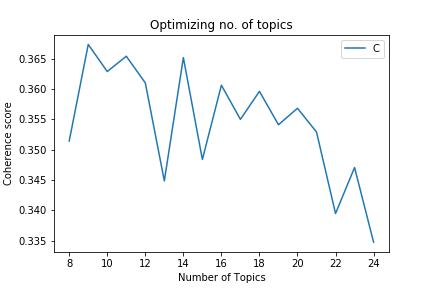
The modeling process involved using the LdaMulticore function from the Gensim package for Python. Coherence score was used to optimize the number of topics for the topic model.
The parameters for the topic model were created as follows:
- Dictionary: The preprocessed texts were used to create a dictionary by using the Gensim package. The dictionary was further filtered for extremes and to have a moderate number of terms.
- Bag of words: The dictionary was then used to create a bag of words for each document in the corpus
- Corpus: The corpus to be used in the model needs to be represented in numbers and not words, which was created using a tfidf model on the bag of words.
The model that I decided to use had the following features/parameters:
- Preprocessed using spacy
- Dictionary with ~1750 terms
- Number of topics: 12
- Passes: 5
- Coherence score: 0.4477
This model was chosen based on examining the coherence scores, pyLDAvis visualizations and overall performance in the recommendations.
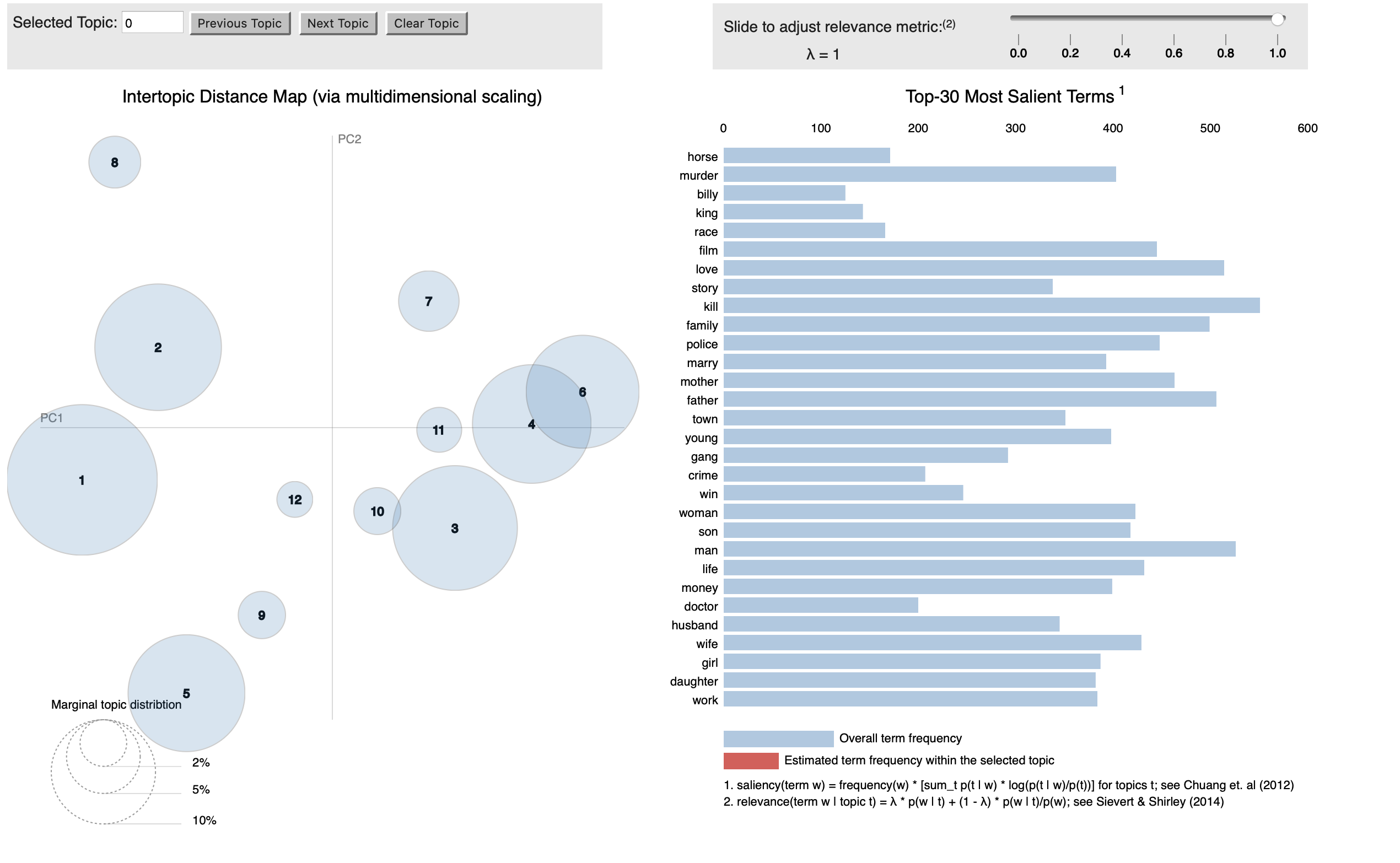
Recommendation system
I created the recommendation system from scratch by defining my own functions. For each movie plot in the corpus, I had a topic distribution using the generated topic model. By using the Jensen-Shannon divergence, I computed the similarity between each of the movie plots and for any given movie the recommendation system would recommend movies most similar to it based on the movie plot texts.
Code for recommendation system
This recommendation system takes user inputs and suggests movies. An example of that is given below:
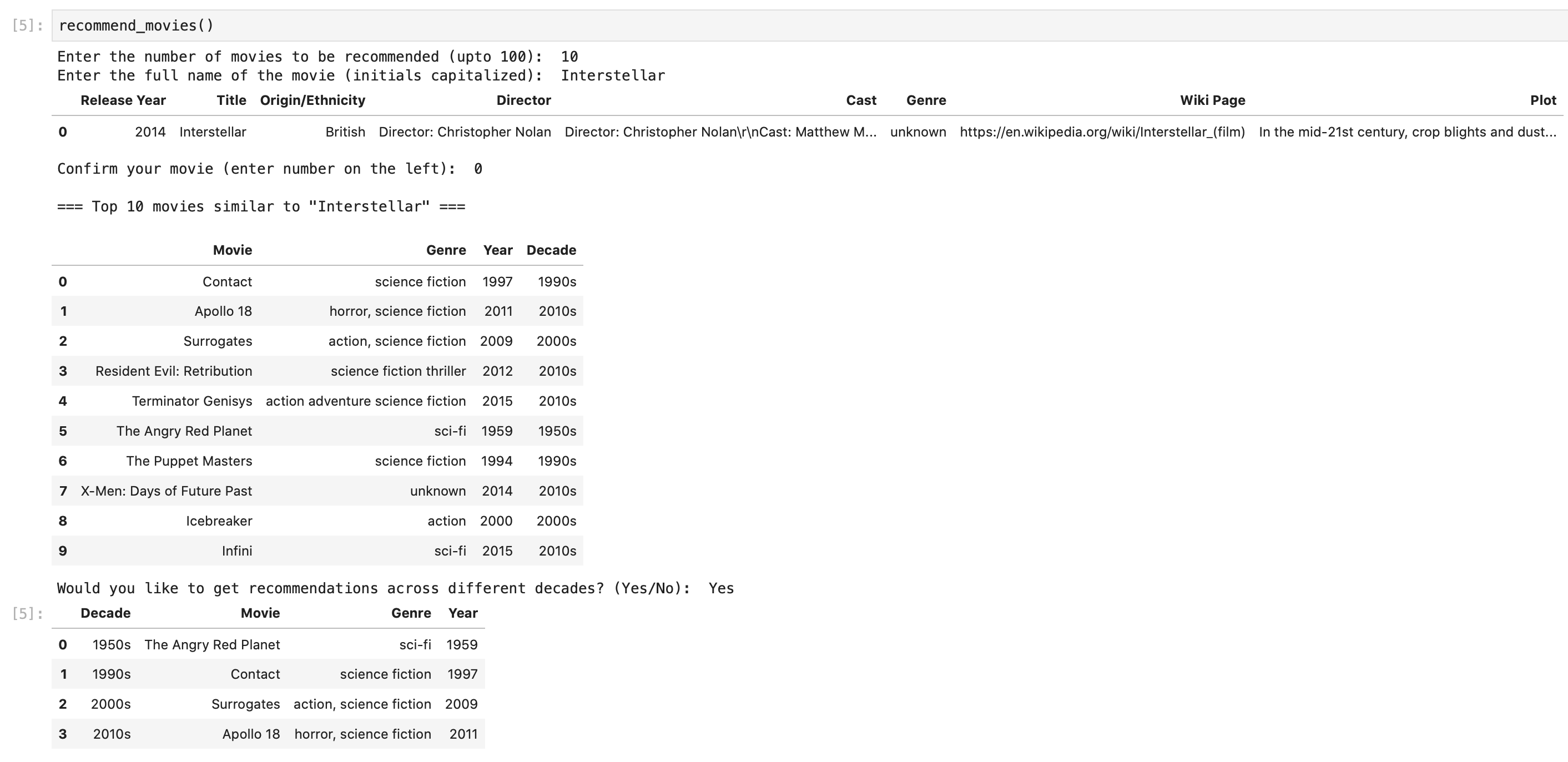
The image shows the user prompts and the recommendations produced. In the example above, 10 similar movies are recommended based on the movie Interstellar. Given that Interstellar is a Sci-fi movie, the recommendation does a pretty decent job in identifying the movies that are similar.
You can download this notebook from my Github Page and try it out for yourself. Do go through the ReadMe section of the project.
More info:
Do check out this video by Andrius Knispelis to get a quick and brief overview of how topic modeling works and how it’s useful.